

Master Data Management (MDM) is more than just organizing data; it’s the foundation for reliable, consistent data across an organization. Data cleansing in Master Data Management is a critical process that ensures data quality, accuracy, and consistency.
This is especially crucial for industries like oil & gas, manufacturing, and pharmaceuticals, particularly in the GCC and MENA regions where massive amounts of data are generated daily.
Effective data cleansing enhances operational efficiency, ensures regulatory compliance, and boosts competitiveness. Let’s dive into the essentials of data cleansing and its transformative role in MDM.
What is Master Data Management?
Master Data Management (MDM) is a comprehensive approach to creating a single, reliable, and trustworthy master record for each entity within an organization. By removing outdated, irrelevant, or inaccurate data, MDM enhances seamless data integration across systems, enabling informed decision-making and higher ROI. MDM plays a vital role in industries handling complex data systems such as oil and gas, where data quality directly impacts operational performance and compliance.
The Importance of Data Cleansing in MDM:
In industries like oil & gas, manufacturing, and pharmaceuticals particularly in data-heavy regions like the GCC and MENA, the need for accurate data management is pressing. The massive data generated across various operations, from exploration to production and customer to vendor management, requires consistent data cleansing to ensure usability and relevance. Data cleansing is the backbone of MDM, improving data reliability and making organizational data integration smooth and effective.
What is Data Cleansing?
Data cleansing, also known as data scrubbing or cleaning, involves identifying and removing inaccurate, incomplete, or duplicate entries from data sets. Through specialized tools and techniques, organizations can ensure high levels of data quality, accuracy, and consistency. This, in turn, facilitates streamlined data integration and empowers sound decision-making that gives organizations a competitive edge.
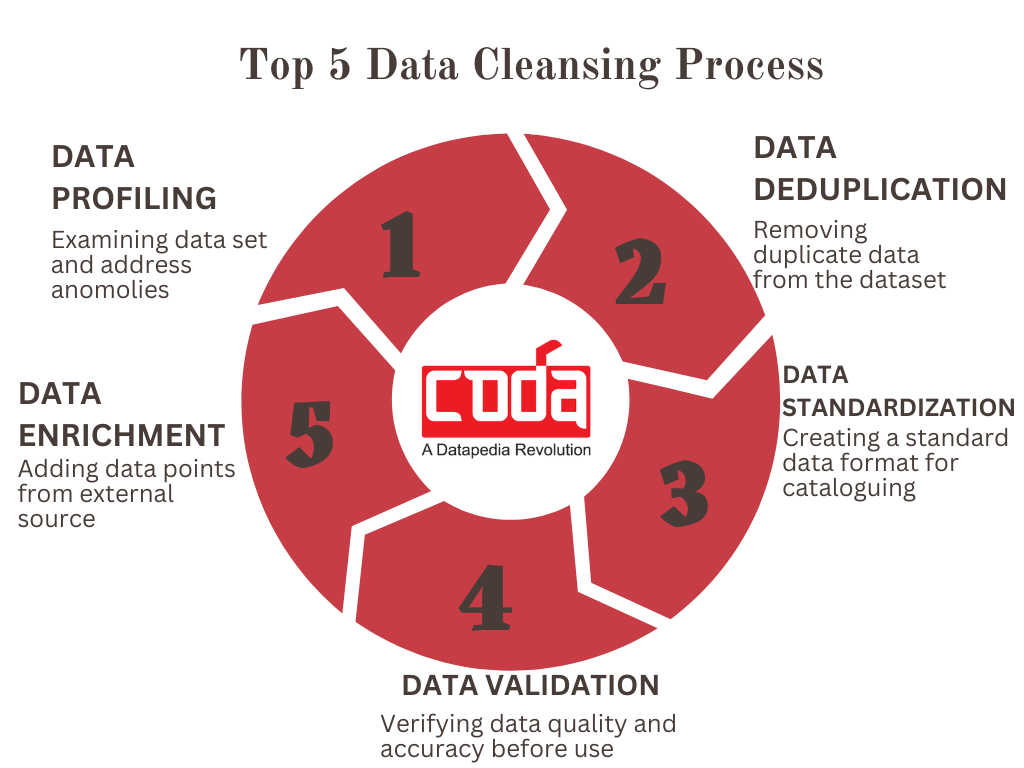
Key Processes in Data Cleansing:
Data cleansing in MDM is a multi-step process aimed at addressing data quality issues. The following are core steps in the data cleansing process, each contributing to improved data reliability:
1. Data Profiling:
Data profiling is the systematic analysis of data patterns and structures to detect duplicate, inaccurate, or irrelevant information. By identifying these issues early, organizations can prevent the proliferation of poor-quality data and ensure a solid data foundation.
2. Data Deduplication:
This process removes redundant, outdated, or irrelevant data entries. Data deduplication reduces storage requirements, optimizes database performance, and supports efficient decision-making.
3. Data Standardization:
Standardizing data involves converting unstructured data into a common format. By creating uniform standards for data cataloging, this process ensures compatibility and smooth integration across systems.
4. Data Validation:
Before data is imported into the MDM system, it must be validated for accuracy and quality. Data validation acts as a final check, ensuring that only high-quality, consistent data enters the organization’s systems.
5. Data Enrichment:
In this step, missing values or additional data points are added to enhance the data set’s completeness and relevance. This can involve pulling in data from both internal and external sources, resulting in a richer, more actionable dataset.
Benefits of Data Cleansing in MDM:
1. Improved Data Accuracy:
Data cleansing significantly improves data accuracy, reducing the likelihood of costly errors that can result from inaccurate or outdated data. For sensitive industries like oil & gas and pharmaceuticals, where data quality impacts safety and compliance, data accuracy is paramount. Cleansing eliminates errors, enhancing the quality of data used across departments.
2. Increased Operational Efficiency:
Clean data streamlines processes, reducing redundancies and optimizing scheduling, production, and resource planning. Industries with complex operations, such as manufacturing, benefit from this increased efficiency, which translates into reduced downtime and boosted productivity.
3. Cost and Time Savings:
Data cleansing helps cut costs by reducing errors and minimizing manual data handling. Clean data reduces time spent correcting mistakes and removes inefficiencies that can lead to unnecessary spending.
4. Regulatory Compliance and Security:
Many industries, particularly those in regulated sectors like oil & gas and pharmaceuticals, must comply with strict data governance standards. Data standardization during cleansing ensures that records meet industry regulations, such as GDPR or HIPAA, while reinforcing security protocols across the organization.
5. Enhanced Data Integration:
Accurate and trustworthy data simplifies data integration, allowing for seamless communication across departments and systems. The standardized data supports smoother cross-departmental integration, reducing errors and improving data flow.
6. Better Decision-making:
High-quality data enables leadership to make informed decisions. By eliminating inaccurate or irrelevant data, data cleansing creates a reliable foundation for data analytics and reporting, supporting more effective decision-making.
Challenges in Data Cleansing:
Despite its advantages, data cleansing presents several challenges. Organizations often face hurdles in ensuring data quality due to the following issues:
1. Inconsistent Data:
Data often comes from diverse sources—some structured, others unstructured—which can create inconsistency. These variances make it difficult for cleansing tools to apply standard processes across all data, increasing the complexity of the task.
2. Time-Intensive Processes:
Data cleansing is often time-consuming, especially when dealing with vast amounts of data. Identifying duplicates, correcting errors, and enriching data requires significant resources and time, which can delay the completion of data projects.
3. Data Governance and Compliance:
Cleansing sensitive data, especially in sectors like oil & gas or healthcare, requires strict adherence to regulatory standards such as GDPR or HIPAA. Ensuring compliance during cleansing can be complex, especially when handling sensitive or personally identifiable information (PII).
How CODASOL Addresses Data Cleansing Challenges:
At CODASOL, we understand the unique challenges of data cleansing and have developed AI/ML-powered solutions to overcome them. Here’s how we streamline data cleansing:
- Automated Data Quality Assessment:
By integrating AI and machine learning, we automate data quality assessment, significantly reducing manual intervention and enhancing accuracy.
- Comprehensive Market Intelligence:
CODASOL’s solutions align with the latest industry standards, including ISO 8000, ISO 14224, ISO 22745, UNSPSC, and ECLASS. This ensures compliance and positions our clients for data excellence in a competitive market.
- Master Data Expertise:
We specialize in assessing critical data types like Material Master, Asset Master, Customer Master, and more, providing a comprehensive view of data quality.
- ERP System Integration:
Our tools are designed for seamless integration with existing ERP systems, ensuring continuity and reducing disruptions across organizational workflows.
Closing Thoughts:
Data cleansing is not just an operational necessity anymore; it’s a competitive advantage. As the demand for reliable data grows, ensuring data quality through cleansing becomes vital. CODASOL leverages advanced AI/ML-driven solutions to streamline data cleansing, minimize manual effort, and meet industry standards like ISO and ECLASS.
By addressing data inconsistencies, regulatory compliance, and ERP integration, we help organizations transform their data into a strategic asset that supports informed decision-making and growth.

Start your journey towards cleaner, more reliable data today
